flowchart LR
A[Écrire le code] --> B[Écrire les tests]
B --> C{Les tests passent ?}
C -->|Non| D[Corriger]
D --> C
C -->|Oui| E[Commit / Push]
E --> F[La CI relance les tests]
Tester, c’est douter
Bien que je vous encourage à douter de tout dans la vie, si cet adage vous est familier, j’espère qu’il ne guide pas votre façon d’écrire du code.
Les tests font partie intégrante du développement logiciel. Ils permettent de confirmer un comportement attendu, de prévenir les régressions, de documenter implicitement les règles métier et d’avoir confiance dans votre code.
Avec autant d’avantages, il serait dommage de douter de leur utilité n’est-ce pas ? 🥁
Il en existe plusieurs types, trop pour les lister ici. Nous nous intéresserons particulièrement aux tests unitaires et aux tests d’intégration. Nous les aborderons comme une étape à part entière, même si en pratique vous devriez tester votre code au fil de son développement.
Le cycle de test
Dans une approche classique, on écrit d’abord le code puis les tests qui le valident. Tant qu’un test échoue, on corrige, et une fois au vert on commit. La CI rejoue alors ces mêmes tests à chaque push pour garantir que rien ne casse dans le temps.
TipEt si on inversait l’ordre ? Le TDD
Le Test Driven Development (développement piloté par les tests) renverse la logique : on écrit le test avant le code. Le cycle tient en trois temps, souvent résumé par red, green, refactor :
- Red : on écrit un test pour une fonctionnalité qui n’existe pas encore. Il échoue, c’est normal.
- Green : on écrit le minimum de code pour faire passer le test.
- Refactor : on améliore le code en gardant le test au vert.
L’intérêt est qu’on ne code que ce qui est nécessaire pour répondre à un besoin exprimé sous forme de test, ce qui force à clarifier le comportement attendu avant l’implémentation. Nous ne ferons pas de TDD strict dans ce projet, mais c’est une méthode qui vaut le détour et que vous croiserez peut-être un jour (Si vous en parlez à la machine à café avec vos devs vous passerez soit pour quelqu’un de détestable soit pour un homme de culture).
Structurer le dossier de tests
Nous utiliserons pytest, la librairie de référence de l’écosystème Python. Rendez-vous dans votre Terminal pour structurer le dossier de tests. On part sur une approche classique : un module de code testé correspond à un module de test.
CautionÀ vous de jouer
Structurez votre dossier de tests en ligne de commande en respectant l’approche un module de code = un module de test :
- Créez le dossier
tests/à la racine du projet - Ajoutez-y un
__init__.pypour en faire un package - Créez un module de test par module à tester :
test_data.pyettest_reporting.py
Solution
mkdir tests
touch tests/__init__.py
touch tests/test_data.py
touch tests/test_reporting.pyAjoutez ensuite les dépendances nécessaires à votre projet. pytest est le framework de test et pytest-cov son extension dédiée à la mesure de couverture, dont nous nous servirons un peu plus loin.
uv add --dev pytest pytest-covPour lancer la suite de tests, la commande à retenir est :
uv run pytest .Par défaut pytest découvre automatiquement tous les fichiers commençant par test_ et exécute les fonctions qu’ils contiennent. Vous pouvez aussi cibler un seul module en lui passant son chemin, pratique quand vous travaillez sur une fonction précise et ne voulez pas relancer toute la suite :
uv run pytest tests/test_data.py
NotePourquoi
--dev ?
Ces dépendances ne sont utiles qu’en phase de développement. Une fois le projet livré en production, pytest et pytest-cov ne servent plus à rien : on ne lance pas de tests dans un conteneur de prod.
En les déclarant comme dépendances de développement, elles sont installées sur votre machine et dans la CI, mais peuvent être exclues de l’image finale. On allège ainsi le projet et on évite d’embarquer du tooling inutile dans notre image Docker.
Les tests unitaires
Les tests unitaires sont les plus granulaires qui existent : ils testent une seule unité de code de manière isolée, typiquement une fonction ou une méthode. L’idée est simple : pour un input donné, on vérifie que l’output correspond exactement à ce qu’on attend, sans aucune dépendance externe (base de données, API, fichier).
C’est la base de toute stratégie de test : rapides à exécuter, faciles à localiser quand ils échouent et ils forcent à écrire des fonctions qui font une seule chose. Si un test unitaire est difficile à écrire, c’est souvent le signe que la fonction testée est trop complexe.
test_data.py
Avant d’écrire nos tests, un mot sur les fixtures. Une fixture pytest est un objet réutilisable, préparé une fois et injecté dans les tests qui en ont besoin. Ici on s’en sert pour créer un petit DataFrame qui simule les données brutes, plutôt que de le recréer dans chaque test.
"""Tests for data.py"""
import pandas as pd
import pytest
from medas_financial_reporting.financial_reporting.data import clean_data
@pytest.fixture
def raw_df():
"""DataFrame minimal simulant les données brutes."""
return pd.DataFrame({
"type_client": ["PP", "PM", "PP"],
"score": ["V", None, "R"],
"score_prev": [None, "O", None],
"id_agent": ["AUTO", "AGT001", "AUTO"],
"drc_complet": [True, False, True],
})Pour rappel, clean_data remplace les score manquants par S, les score_prev manquants par N, et tout id_agent différent de AUTO par MANUEL.
CautionÀ vous de jouer
En partant de la fixture raw_df, écrivez un test par comportement attendu. Chaque test prend raw_df en argument, appelle clean_data et vérifie le résultat avec un assert. Couvrez les cas suivants :
- les
scoremanquants sont bien remplacés parS - les
score_prevmanquants sont bien remplacés parN - un
id_agentvalantAUTOresteAUTO, tout autre devientMANUEL - après nettoyage,
scoreetscore_prevne contiennent plus aucunNaN clean_datane supprime aucune ligne
Règle d’or : un test vérifie un seul comportement et son nom doit dire ce qu’il vérifie.
Solution
def test_clean_data_fills_score(raw_df):
"""Les NaN de score sont remplacés par S."""
result = clean_data(raw_df)
assert result["score"].iloc[1] == "S"
def test_clean_data_fills_score_prev(raw_df):
"""Les NaN de score_prev sont remplacés par N."""
result = clean_data(raw_df)
assert result["score_prev"].iloc[0] == "N"
assert result["score_prev"].iloc[2] == "N"
def test_clean_data_id_agent(raw_df):
"""Les agents non AUTO sont remplacés par MANUEL."""
result = clean_data(raw_df)
assert result["id_agent"].iloc[0] == "AUTO"
assert result["id_agent"].iloc[1] == "MANUEL"
def test_clean_data_no_nulls(raw_df):
"""Après nettoyage, score et score_prev ne contiennent plus de NaN."""
result = clean_data(raw_df)
assert result["score"].isna().sum() == 0
assert result["score_prev"].isna().sum() == 0
def test_clean_data_preserves_rows(raw_df):
"""clean_data ne supprime pas de lignes."""
result = clean_data(raw_df)
assert len(result) == len(raw_df)Quelques explications maintenant que vous avez essayé.
Pourquoi ne pas utiliser les vraies données dans la fixture ? Pour deux raisons. Elles sont trop volumineuses pour des tests unitaires censés être instantanés et surtout parcequ’elles introduiraient une dépendance externe. Or on veut ici tester la logique de nos transformations, pas la lecture d’un fichier distant ou local. Un DataFrame écrit à la main suffit et reste totalement sous contrôle.
Sur la façon d’écrire les tests, on s’impose une règle simple : un test par comportement attendu. On prévoit aussi les cas limites, comme la suppression involontaire de lignes. Chaque test doit vérifier une seule chose. Ainsi lorsqu’un test échoue, vous savez immédiatement quoi chercher.
Vous vous demandez peut-être pourquoi get_data n’est pas testée ici. La réponse découle directement de ce qu’on vient de dire : elle fait un appel réseau vers MinIO, ce qui en fait un test d’intégration et non un test unitaire. Retenez bien qu’un test unitaire ne dépend de rien d’externe, on la testera donc dans la section suivante.
test_reporting.py
Pour tester fill_indicators et write_data_to_excel, on a besoin d’un fichier Excel. Là encore on ne va pas utiliser un vrai fichier du projet mais des fixtures : un workbook minimal créé à la volée et un petit DataFrame simulant des données nettoyées.
Cette fois je vous laisse écrire les fixtures vous-mêmes.
CautionÀ vous de jouer
Dans tests/test_reporting.py, écrivez deux fixtures :
minimal_workbook: crée un fichier.xlsxtemporaire contenant deux feuilles,DATAetIndicateurs, et renvoie son chemin. Utilisez la fixture intégréetmp_pathdepytestpour écrire dans un dossier temporaire, etopenpyxlpour construire le workbook.sample_df: renvoie un petit DataFrame avec les colonnestype_client,score,score_prev,id_agentetdrc_complet.
Indice : tmp_path est une fixture fournie par pytest, vous n’avez qu’à la déclarer en argument pour obtenir un dossier temporaire propre à chaque test.
Solution
"""Tests for reporting.py"""
import pandas as pd
import pytest
from openpyxl import Workbook, load_workbook
from medas_financial_reporting.financial_reporting.reporting import (
fill_indicators,
write_data_to_excel,
)
@pytest.fixture
def minimal_workbook(tmp_path):
"""Workbook minimal avec les feuilles DATA et Indicateurs."""
path = tmp_path / "test_reporting.xlsx"
wb = Workbook()
wb.active.title = "DATA"
wb.create_sheet("Indicateurs")
wb.save(path)
wb.close()
return path
@pytest.fixture
def sample_df():
"""DataFrame minimal simulant les données nettoyées."""
return pd.DataFrame({
"type_client": ["PP", "PM"],
"score": ["V", "S"],
"score_prev": ["N", "O"],
"id_agent": ["AUTO", "MANUEL"],
"drc_complet": [True, False],
})Une fois les fixtures en place, on peut écrire les tests. Voici ceux des deux fonctions :
Voir le code
class TestFillIndicators:
def test_countif_formula(self, minimal_workbook):
fill_indicators(input_path=minimal_workbook, output_path=minimal_workbook)
wb = load_workbook(minimal_workbook, data_only=False)
ws = wb["Indicateurs"]
assert ws["E8"].value == '=COUNTIF(DATA!B:B, "PP")'
wb.close()
def test_sum_formula(self, minimal_workbook):
"""Vérifie que la formule SUM est correctement générée."""
fill_indicators(input_path=minimal_workbook, output_path=minimal_workbook)
wb = load_workbook(minimal_workbook, data_only=False)
ws = wb["Indicateurs"]
assert ws["E10"].value == "=SUM(E8:E9)"
wb.close()
def test_countifs_formula(self, minimal_workbook):
"""Vérifie que la formule COUNTIFS est correctement générée."""
fill_indicators(input_path=minimal_workbook, output_path=minimal_workbook)
wb = load_workbook(minimal_workbook, data_only=False)
ws = wb["Indicateurs"]
assert ws["E14"].value == '=COUNTIFS(DATA!B:B, "PP", DATA!D:D, "V")'
wb.close()
def test_unknown_formula_raises(self, minimal_workbook):
"""Une formule inconnue dans INDICATORS lève une ValueError."""
from medas_financial_reporting import config
original = config.INDICATORS.copy()
config.INDICATORS.append({"row": 99, "formule": "UNKNOWN", "args": []})
with pytest.raises(ValueError, match="Formule inconnue"):
fill_indicators(input_path=minimal_workbook, output_path=minimal_workbook)
config.INDICATORS = original
class TestWriteDataToExcel:
def test_data_inserted(self, minimal_workbook, sample_df):
"""Vérifie que les données sont bien insérées dans la feuille DATA."""
import shutil
from medas_financial_reporting.config import LOCAL_TEMPLATE, LOCAL_TMP_DIR
LOCAL_TMP_DIR.mkdir(exist_ok=True)
shutil.copy(minimal_workbook, LOCAL_TEMPLATE)
write_data_to_excel(sample_df)
wb = load_workbook(LOCAL_TEMPLATE, data_only=False)
ws = wb["DATA"]
assert ws.cell(row=1, column=1).value == "type_client"
assert ws.cell(row=2, column=1).value == "PP"
wb.close()Le twist par rapport au module précédent : on regroupe ici les tests dans des classes. La classe TestFillIndicators rassemble tous les tests de fill_indicators, et TestWriteDataToExcel ceux de write_data_to_excel. Ce n’est pas obligatoire mais c’est une convention pytest pratique : elle facilite la lecture et permet de vérifier d’un coup d’œil qu’aucun comportement n’a été oublié pour une fonction donnée.
La couverture de tests
En parlant de ne rien oublier, ce serait pratique d’avoir un outil qui affiche la part de notre code réellement couverte par les tests. Bonne nouvelle, c’est le rôle de pytest-cov, la dépendance ajoutée plus tôt. Pour générer le rapport :
uv run pytest --cov=src/medas_financial_reporting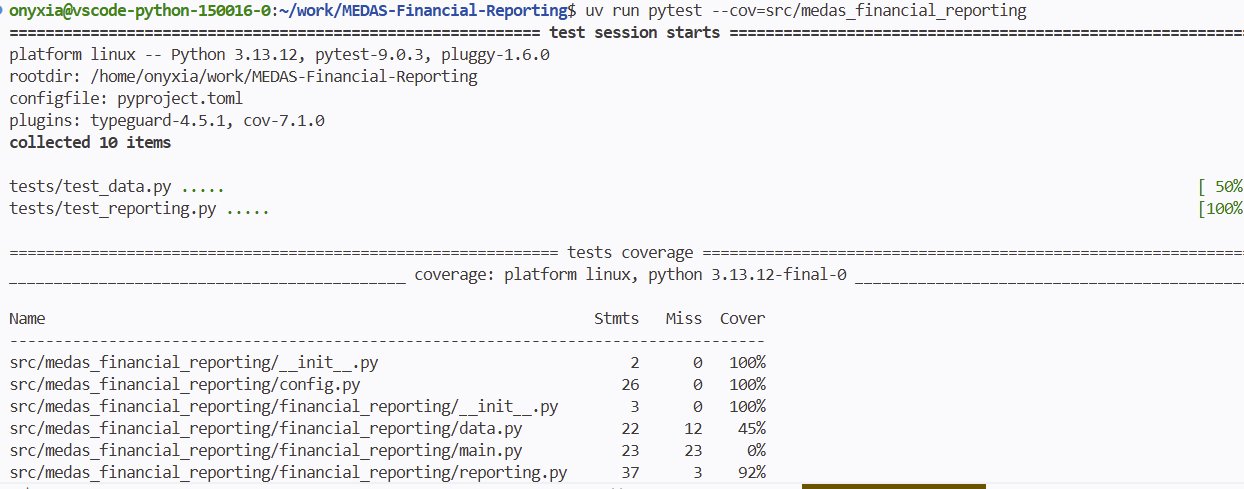
WarningLa couverture est un indicateur, pas un objectif
Il peut être tentant de viser 100% partout, mais ce chiffre ne traduit en rien la qualité ni la fiabilité de vos tests. Si un jour quelqu’un vous lance “c’est quoi ce code sans 100% de coverage ?” : restez calme, prenez une grande inspiration et essayez de lui expliquer que ce qu’il demande n’a pas de sens. (avec tout le respect bien sûr)
Toutefois, l’inverse est tout aussi vrai : un coverage très faible avec un “pas de souci, ça marche sur mon ordi ” n’est pas plus sérieux. Le bon réflexe est de voir la couverture comme un signal. Si le projet évolue plus vite que les tests et que le coverage chute, c’est souvent le signe qu’il faut revoir vos méthodes de développement.
Pour en revenir à notre rapport, voir main.py à 0% peut sembler gênant. Mais si on repense à notre architecture, c’est normal : main.py est un module d’orchestration. Il ne fait qu’appeler des fonctions déjà testées individuellement. On ne va ni les retester, ni vérifier qu’on les a appelées dans le bon ordre.
La solution est simple : on l’exclut du rapport. Dans pyproject.toml :
[tool.coverage.run]
omit = [
"src/medas_financial_reporting/financial_reporting/main.py",
"src/medas_financial_reporting/storage.py",
]
NoteUn contrat avec votre vous du futur
En excluant main.py du coverage, vous vous engagez à ne jamais y mettre de logique critique qui mériterait d’être testée. main.py doit rester un module d’orchestration pur. Le jour où vous ressentez l’envie d’y glisser un traitement, même minime, c’est le signe qu’il faut plutôt créer une fonction dans le module approprié.
Les tests d’intégration
Là où les tests unitaires ne dépendent de rien d’externe, les tests d’intégration vérifient que notre code communique bien avec des éléments extérieurs. get_data() en est le parfait exemple : elle effectue un appel réseau vers MinIO. On ne teste plus ici la logique de transformation mais le fait que nos composants arrivent à dialoguer avec le stockage distant.
Créez un nouveau fichier tests/test_integration.py :
Voir le code
"""Tests d'intégration"""
import pandas as pd
import pytest
from medas_financial_reporting.financial_reporting.data import get_data
@pytest.mark.integration
def test_get_data_returns_dataframe():
"""Vérifie que get_data retourne bien un DataFrame non vide."""
df = get_data()
assert isinstance(df, pd.DataFrame)
assert len(df) > 0
@pytest.mark.integration
def test_get_data_expected_columns():
"""Vérifie que les colonnes attendues sont présentes."""
df = get_data()
expected = {"type_client", "score", "score_prev", "id_agent", "drc_complet"}
assert expected.issubset(set(df.columns))
@pytest.mark.integration
def test_get_data_schema_valid():
"""Vérifie que les valeurs respectent le domaine métier attendu."""
df = get_data()
assert df["type_client"].isin(["PP", "PM"]).all()
assert df["drc_complet"].dtype == boolUn mot sur le décorateur @pytest.mark.integration. Il sert à marquer ces tests pour pouvoir les lancer séparément des tests unitaires. C’est important car les tests d’intégration sont plus lents et nécessitent un accès réseau : on ne veut pas forcément les jouer à chaque fois. Pour garder un comportement symétrique, ajoutez @pytest.mark.unit devant chacun de vos tests unitaires.
Déclarez ensuite ces marqueurs dans pyproject.toml, sinon pytest émettra un avertissement pour marqueur inconnu :
[tool.pytest.ini_options]
markers = [
"unit: tests unitaires",
"integration: tests d'intégration",
]Vos commandes deviennent alors :
# Tests unitaires uniquement
uv run pytest -m unit
# Tests d'intégration uniquement
uv run pytest -m integration
# Tous les tests
uv run pytest
NotePour aller plus loin : les tests end-to-end (E2E)
Les tests E2E (end-to-end) vont encore plus loin que les tests d’intégration : ils valident la chaîne complète, du déclenchement du pipeline jusqu’au résultat final. Là où un test d’intégration vérifie qu’un composant communique avec un autre, un test E2E lance tout main() et contrôle que le reporting est bien généré localement, uploadé sur MinIO et correctement rempli.
On utilise ici une fixture de portée session avec autouse=True pour ne lancer le pipeline qu’une seule fois, puis chaque test inspecte le résultat.
Solution
"""Tests End-to-End."""
import pytest
from openpyxl import load_workbook
from medas_financial_reporting.config import LOCAL_OUTPUT, S3_BUCKET, S3_OUTPUT_KEY
from medas_financial_reporting.financial_reporting.main import main
from medas_financial_reporting.storage import get_fs
@pytest.fixture(scope="session", autouse=True)
def run_pipeline():
"""Lance le pipeline une seule fois pour tous les tests E2E."""
main()
@pytest.mark.e2e
def test_reporting_local_exists():
"""Vérifie que le reporting a bien été généré localement."""
assert LOCAL_OUTPUT.exists()
@pytest.mark.e2e
def test_reporting_uploaded_to_minio():
"""Vérifie que le reporting est bien présent sur MinIO."""
fs = get_fs()
assert fs.exists(f"{S3_BUCKET}/{S3_OUTPUT_KEY}")
@pytest.mark.e2e
def test_reporting_contains_expected_sheets():
"""Vérifie que le reporting contient les feuilles attendues."""
wb = load_workbook(LOCAL_OUTPUT)
assert "DATA" in wb.sheetnames
assert "Indicateurs" in wb.sheetnames
wb.close()
@pytest.mark.e2e
def test_indicators_are_filled():
"""Vérifie que les indicateurs ne sont pas vides."""
wb = load_workbook(LOCAL_OUTPUT)
ws = wb["Indicateurs"]
assert ws["E8"].value is not None
assert ws["E10"].value is not None
wb.close()Sans oublier d’ajouter le marqueur e2e dans pyproject.toml :
[tool.pytest.ini_options]
markers = [
"unit: tests unitaires",
"integration: tests d'intégration",
"e2e: tests end-to-end",
]
TipGit time
Pensez à commit et push votre travail avant de passer à la suite.